Taking Models from Data Scientists to Users(Part 5): Container
Container - boxing code dependencies with Docker
This is a series of write-up on a modern data pipeline implementaiton with case study of Tyco Cam security solutions using various data tooling features like Pacyderm, Kubernetes, Docker, Tensorflow and Storage infrastructre like AWS
Table of Contents
- Intro - Analytics and Deployment: Why should Data Scientist care about Production?
- Cloud Locations: Case for Objects Storage
- Model and Framework selection in Production: A Case of Object Detection with TensorFlow
- Building the full Data Pipeline - I
- Container- boxing code dependencies with Docker
- Building the full Data Pipeline - II
- Update, Maintain and Scale your Data Science Pipeline
This is the fifth article in the series discussing the elements required to make a locally developed data science model to production-ready machine
In continuation of our ongoing case study of Tyco, this post hopes to choose one more critical component of our production model i.e. the code infrastructure. Specifically, the way to import underlying dependencies that are needed to run the operations of identifying objects in images to a certain degree. We have already identified options of TensorFlow(Object Detection), Pachyderm(data versioning) and miscellaneous Python libraries including 3rd party APIs to send email, read images, etc.
One general challenge with leaning a new library/feature is not the fundamentals but the installation and configuration part of it. There are many dependencies that need to be tweaked just right to be able to get started. One solution to tackle, that also has been gaining popularity, is the re-branded version of an old concept known as Software Containers. In very simple terms, container is a “box” that contains the bare essentials to run an application. To be more specific, it is an isolated instance that contains resources/file systems that are required to run typical a single application with all of its dependencies - binaries/libraries/packages.
Did it sound like VM(Virtual Machine) to you?
VMs and containers aim to solve a single purpose but in two different ways. Primarily, individual VMs contains those many entire Guest OS’es for each application that it needs to run as compared to Container which shares the single OS(and other resources) among various apps. This article goes on to explain in detail about Docker containers which is the most popular container technology that exists on the market today.

Why Tyco data pipelines needs Containers
Tyco pipeline has multiple pieces (Validation Checking, Object Detection, Threat Detector, Dashboards and Data versioning) that it needs to run on Cloud instance(like EC2). There are a variety of choices available for deployment like these.
Traditionally deployment had been approached by replicating the code infrastructure from a local machine on to a cloud instance piece-by-piece i.e. manually verifying and installing it. It used to take a lot of time and effort-repetition without ensuring the certainty of a clean deployment.
Especially in the context of Data Science, where crucial decisions are based on a model,s integrity of the result is very important and any uncertainty will likely dissuade adoption further. For instance, few numbers of occurrences of delayed deployment or inaccurate object detection will not sit well with customer’s perception of the system reliability and they may not fully trust the system in future. Similar examples exist in the Insurance industry where a compliance-mandate flag gets raised, if a model cannot reproduce the results of claim-rejection due to uncertain code infrastructure. Plus, customers of the model will always be wary of the result even when it gets fixed. Human factors like these are critical for the internal branding of your deployed model.
These issues were somewhat solved with the arrival of VM with partitions in the same machine. It was a neat solution but there still existed problems regarding the size(size hinders portability) and efficiency(unused resources like duplicated instances of full OS)
Taking above two issues and solutions in different combination would lead us to ponder over following options:
- one application per instance - inefficient and costly
- multiple/instance - can create conflict, complex to maintain
- multiple VM per machines: -inefficient
Fortunately, there is a savior option available in Containers that resolves above issues to a large extent.
Software Container groups one application+dependency in one unit. These units are created for each separate application and share same underlying kernel including memory, bit usage, CPU memory etc. If one unit is not using it, others units are free to use it
Additionally, container will somewhat abstract the complicated integration efforts of a Data Scientist team. This is vital in an organization setting where the supposedly experts in the technical details (think Software Engineers etc.) are too not familiar with typical Data Science stack(TensorFlow, Shiny, Keras). What it means that without containers it’d be a full time job of team to assist in setting up the complicated pieces which organizations are happy to forgo.
Docker
The release of container by Docker, Inc.in 2013 have reshaped the enterprise-level virtualization solutions for good. Docker architecture and usability designs immensely helped in easy adaptability by the developer’s community. Previous generation containers were difficult to use until Docker made it easy. Docker provided a certain implementation of container that is now ubiquitous. It is as popular in startup community as in big enterprises.
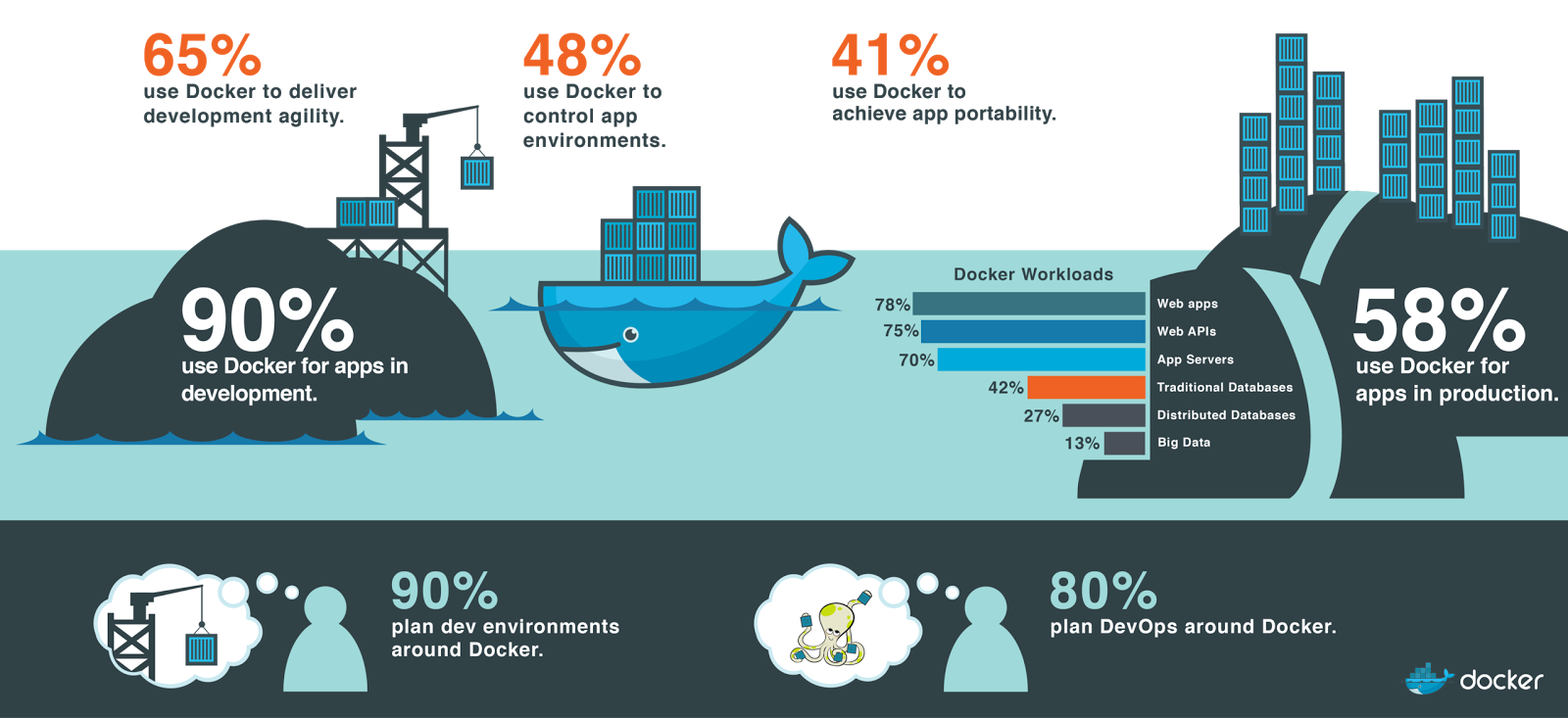
Some Docker Terminologies
- image - package that includes app & dependencies(like a zip file of code). It determines how an application is to built and forms the basis of container. It is more permanent.
- container - a running instance of an image in from which the application service is spun. It is a temporary instantiation in a way that an image can be used to deploy multiple Docker containers as and when needed.
- engine - the application(daemon process) that builds, ships and runs container(and by extension images) which because of the engine versatility allows it to deploy it on physical/virtual or data center or cloud
- registry - where you store, tag, and get images(like Github, Netflix of docker images). Most famous public registry is Docker Hub where some popular images are officially supported by creators e.g. Python, TensorFlow, r-base
- Dockerfile - a text file that tells the engine how to build an image with
docker build. It is written in layers which builds the image in the layer.
Layering is a key design-aspect of Docker and derives its importance from it. Adding or removing a layer helps to reduce overheads and increase the re-usage of processing. Every Docker image starts with a Base Image and then specific process-dependent images.
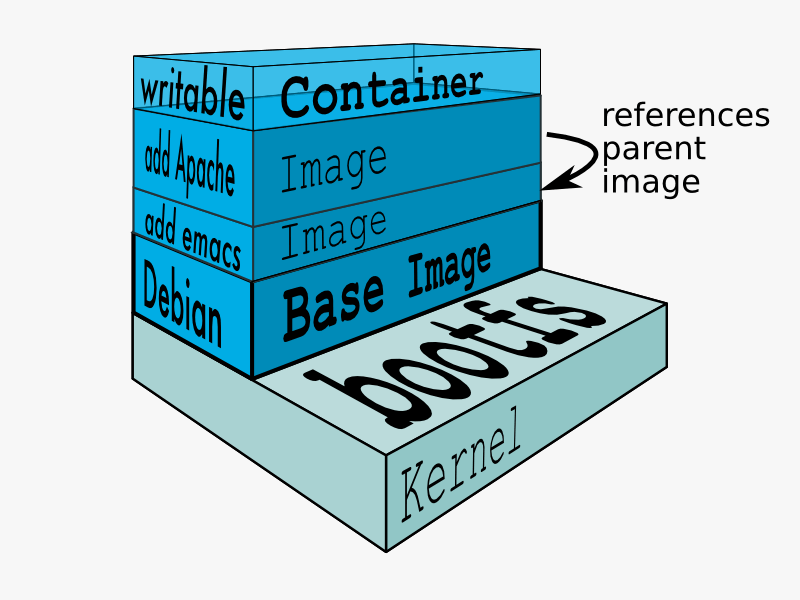
Packages are lightweight(generally in MBs). It could be slow for the first time running due to the addition of an internal image on top of docker image but otherwise, there is no lag. Security model with Docker is slightly different, not in scope for this article but it is something that also teams needs to be aware of. Performance may never be issue excluding design where pipelines require a lot of data transfer from the external environment. It is recommended that whatever need is to be put up as a container
Thus In case of Tyco, all the multiple pieces (Validation Checking, Object Detection, Threat Detector, Dashboards and Data versioning) can be run as separate Docker containers in EC2.
Data Versioning container powered by Pachyderm is not represented in the data pipeline in the earlier post by a separate process as its working is present ubiquitously. “Under-the-hood” it ensures right data is pointed to the right container for an effective data flow.
These images will be run on docker engine that interfaces with underlying OS and share resources thereby saving useful infrastructure and operational bill for Tyco.
Docker implementation steps in a deployment cycle(steps 2-3-5 are usually automated)
- Develop application which is your usual model
- Build a Docker image for the app with Docker engine
- Upload the image to a registry
- Deploy a Docker container, based on the image and from the registry, to a VM(the only requirement for VM is to have Docker; EC2 needs to have Docker-enabled instance)
Step 1 is followed by creating a Dockerfile and moving the application codebase to Github
Sample Dockerfile to build image of Object Detection TensorFlow on the pipeline
# FROM specifies the Base Image layer pulled from public registry
FROM deeone/tensorflow-object-detection:1.2.1
#RUN will layer on Base Image by installing and putting python image
RUN apt-get update && apt-get install -y python-tk \
&& apt-get clean && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
#ADD copies infer.py(object detection python code) to path
ADD infer.py /tensorflow/models/object_detection/

Final Points
Containers provide excellent efficiency to the Tyco’s data scientist team when compared with VM. They are essential components of a standardized workflow that works everywhere.They allow packaging of pipelines in an isolated and self-contained manner. This makes it easy to implement pipelines easy across different platforms.
Number of Containers to be deployed is first determined by the phases, expected workload on a stage(more the load, more containers), and special requirements of the model. For instance, if same TF is to be used without any performance degradation then then independent TF can be separately containerized whereas if distributed TF on GPUs, needs to be used then deployment in one container and all of the processes can be accessed this instance
Next Steps
After deployment of Container, there are still many gaps that exist hindering it to become an automated pipeline. These are mainly:
-
There is a gap of managing automated data-flow and sequence of steps i.e. get data at the right place. This will be done with Pachyderm.
-
There is a need to handle container load balancing, allocating resources and manage and schedule the containers. Automating these steps is crucial otherwise the alternative would be to utilize support level DevOps doing all the work. This will be done with Kubernettes(K8s).